vendure-data-hub-plugin
Creating Pipelines
Build data pipelines using the visual drag-and-drop editor.
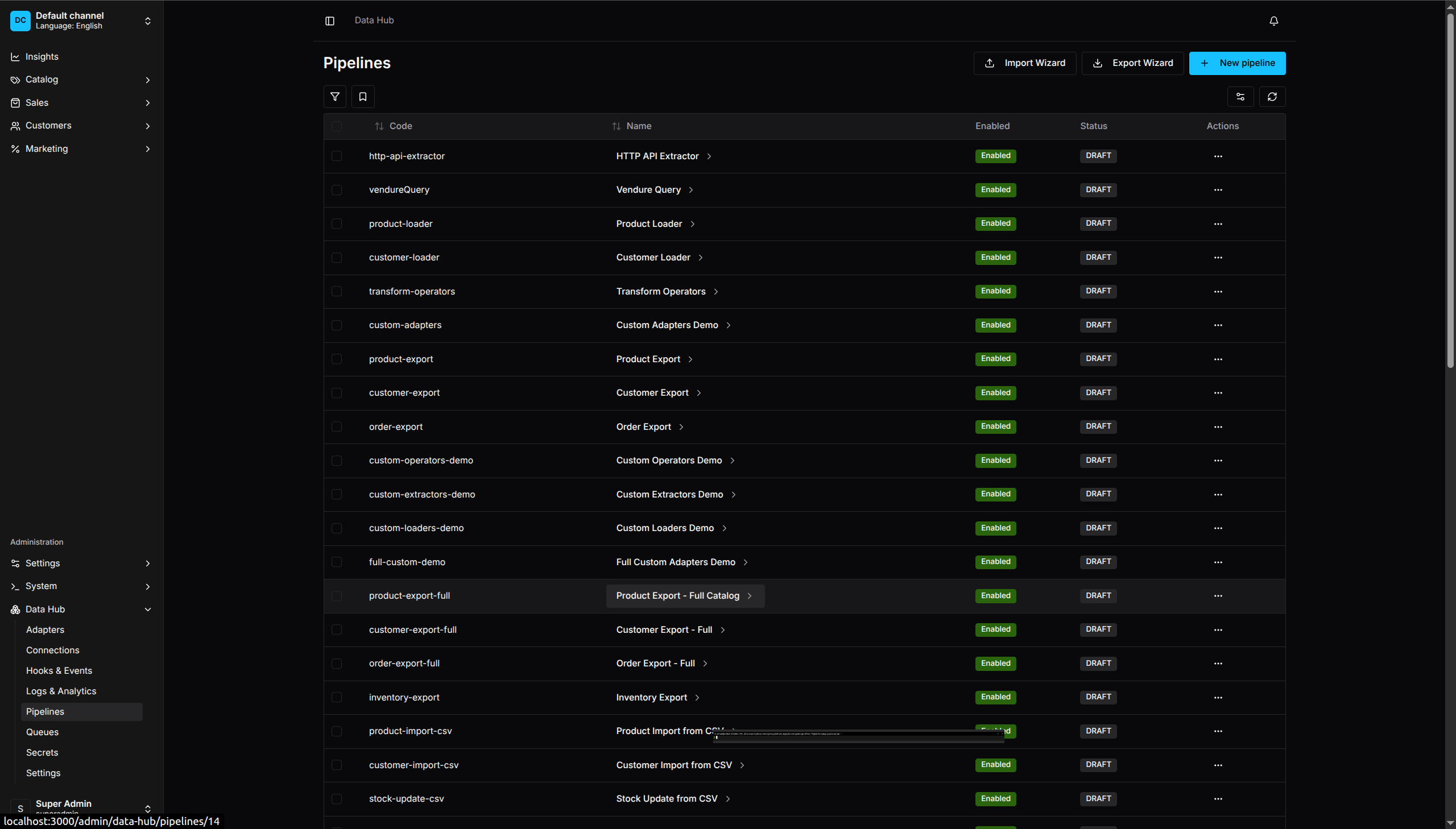
Pipeline Management - View and manage all your data pipelines
Creating a New Pipeline
- Go to Data Hub > Pipelines
- Click Create Pipeline
- Enter:
- Code - Unique identifier (lowercase, hyphens allowed)
- Name - Human-readable name
- Description - Optional description
- Click Create
The Pipeline Editor
The editor has three main areas:
- Toolbar - Save, run, and validate actions
- Canvas - Drag-and-drop area for building pipelines
- Sidebar - Step configuration panel
Simple Mode
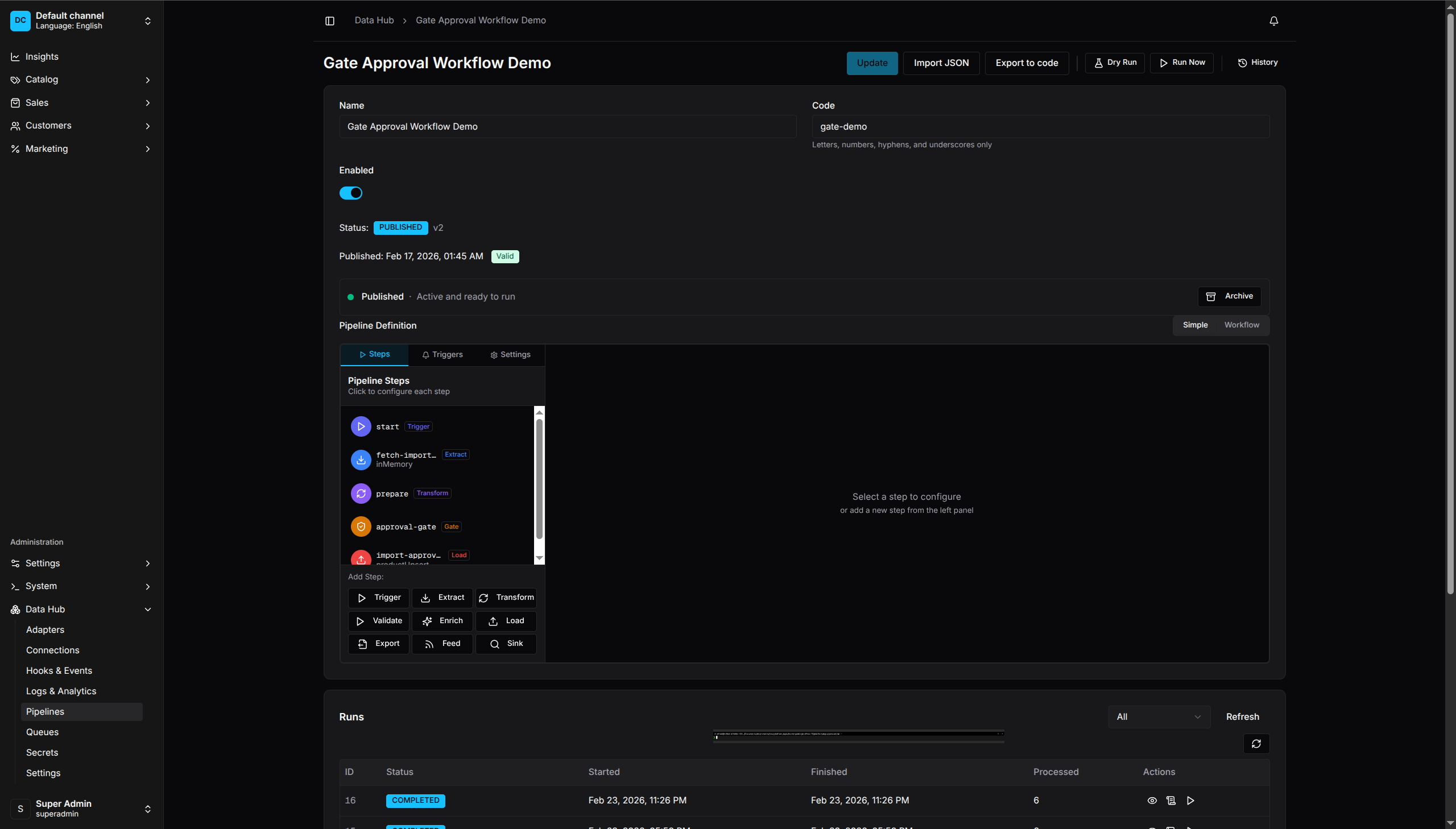
Simple Mode - Step-by-step list view for building pipelines
Workflow Mode
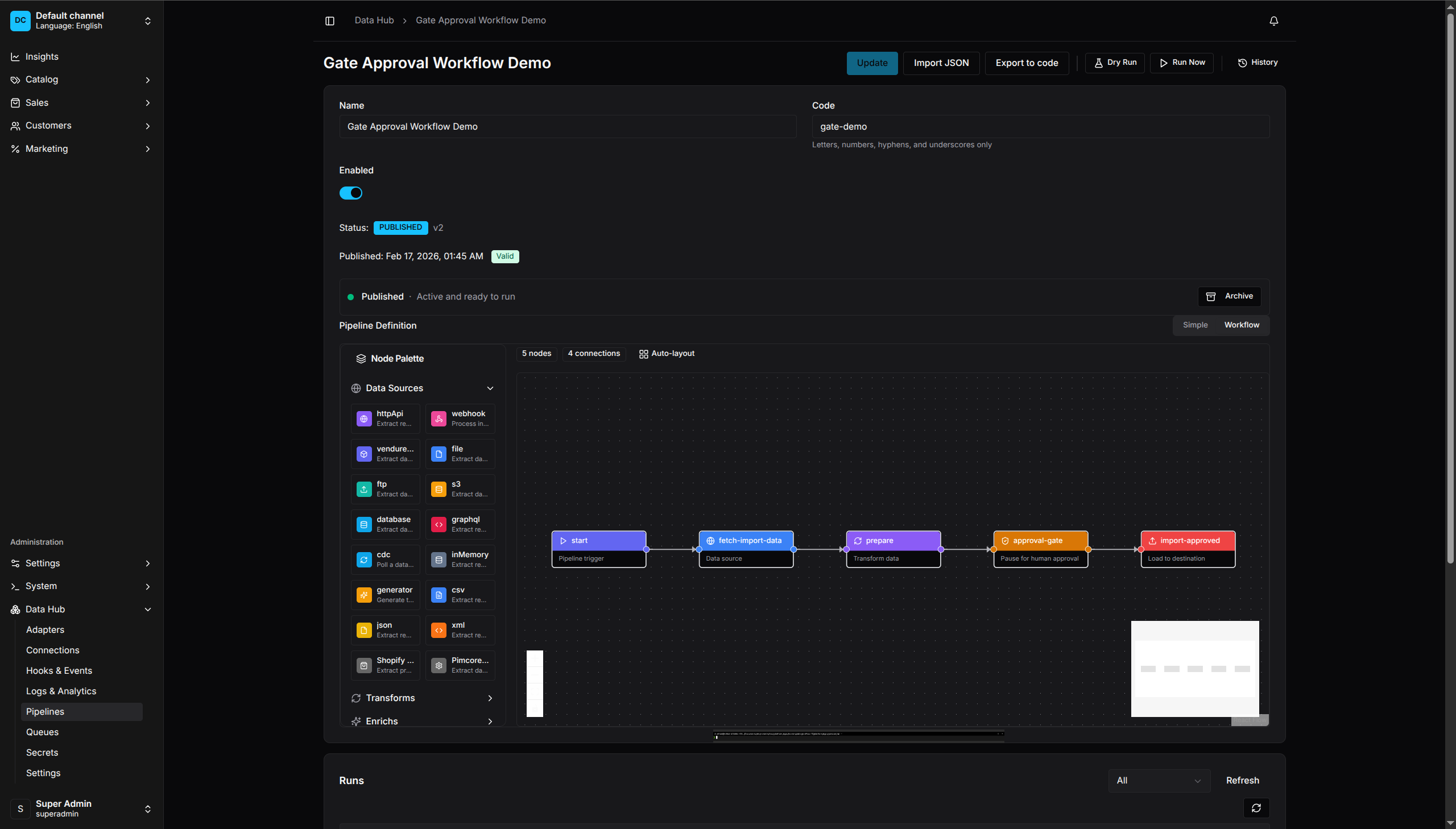
Workflow Mode - Visual drag-and-drop canvas with node palette
Adding Steps
Trigger Step
Every pipeline needs a trigger to define how it starts.
- Drag a Trigger from the palette
- Configure the trigger type:
- Manual - Run via UI or API
- Schedule - Cron-based scheduling
- Webhook - HTTP endpoint trigger
- Event - Vendure event trigger
Extract Step
Extract steps pull data from sources.
- Drag an Extract node
- Select an adapter:
- HTTP API (
httpApi) - REST API endpoints with pagination, authentication, and retry support - File (
file) - Parse CSV, JSON, XML, XLSX, NDJSON, TSV files - GraphQL (
graphql) - External GraphQL endpoints - Vendure Query (
vendureQuery) - Vendure entity data
- HTTP API (
- Configure the adapter settings
- Connect to the trigger
Transform Step
Transform steps modify records.
- Drag a Transform node
- Add operators:
- Click Add Operator
- Select operator type
- Configure parameters
- Operators execute in order
- Connect to the previous step
Load Step
Load steps create or update Vendure entities or send data externally.
- Drag a Load node
- Select a loader:
- Product (
productUpsert) - Create/update products - Variant (
variantUpsert) - Create/update product variants - Customer (
customerUpsert) - Create/update customers - Collection (
collectionUpsert) - Create/update collections - Promotion (
promotionUpsert) - Create/update promotions - Stock (
stockAdjust) - Adjust inventory levels - Order Note (
orderNote) - Add notes to orders - Order Transition (
orderTransition) - Change order states - REST Post (
restPost) - Send data to external APIs
- Product (
- Configure:
- Strategy - CREATE, UPDATE, UPSERT, SOFT_DELETE, or HARD_DELETE
- Field Mappings - map source fields to entity fields
- Connect to the previous step
Connecting Steps
- Click the output port (right side) of a step
- Drag to the input port (left side) of another step
- Release to create a connection
Connections show the data flow direction. A record must pass through connected steps in order.
Step Configuration
Click a step to open its configuration panel:
Common Settings
- Key - Unique step identifier
- Throughput - Batch size, concurrency, rate limiting
- Async - Run asynchronously (advanced)
Adapter Settings
Each adapter has specific settings. See Reference for details.
Branching with Route
Route steps split data flow based on conditions:
- Drag a Route node
- Add branches:
- Branch Name - Identifier for the branch
- Condition - Field, operator, value
- Connect each branch to different steps
- Optionally set a default route
Example: Route products by category:
- Branch “electronics”: category equals “electronics”
- Branch “clothing”: category equals “clothing”
- Default: general processing
Validating Pipelines
Before running, validate your pipeline:
- Click Validate in the toolbar
- Review any issues:
- Missing required fields
- Invalid configurations
- Disconnected steps
Fix all issues before saving.
Saving Pipelines
- Click Save in the toolbar
- The pipeline is saved to the database
- Code-first pipelines cannot be edited via UI (read-only)
Running Pipelines
Manual Run
- Click Run in the toolbar
- Confirm the run
- Monitor progress in the Runs view
With Parameters
Some pipelines accept input parameters:
- Click Run with Parameters
- Enter parameter values
- Click Run
Pipeline States
| State | Description |
|---|---|
| Draft | Not yet saved or validated |
| Enabled | Ready to run, schedules active |
| Disabled | Cannot be run, schedules inactive |
| Running | Currently executing |
Duplicating Pipelines
- Open the pipeline list
- Click the menu (⋮) on a pipeline
- Select Duplicate
- Edit the new pipeline’s code and name
Deleting Pipelines
- Open the pipeline list
- Click the menu (⋮) on a pipeline
- Select Delete
- Confirm deletion
Note: Deleting a pipeline removes all run history.
Hooks
Hooks allow you to execute custom code at specific stages of pipeline execution. Use hooks to modify data, send notifications, trigger other pipelines, or integrate with external systems.
Hook Stages
Data Processing Stages:
| Stage | When It Runs | Can Modify Records |
|---|---|---|
BEFORE_EXTRACT |
Before data extraction | Yes (seed records) |
AFTER_EXTRACT |
After data is extracted | Yes |
BEFORE_TRANSFORM |
Before transformation | Yes |
AFTER_TRANSFORM |
After transformation | Yes |
BEFORE_VALIDATE |
Before validation | Yes |
AFTER_VALIDATE |
After validation | Yes |
BEFORE_ENRICH |
Before enrichment | Yes |
AFTER_ENRICH |
After enrichment | Yes |
BEFORE_ROUTE |
Before routing | Yes |
AFTER_ROUTE |
After routing | Yes |
BEFORE_LOAD |
Before loading to Vendure | Yes |
AFTER_LOAD |
After loading | Yes |
BEFORE_EXPORT |
Before file export | Yes |
AFTER_EXPORT |
After file export | Yes |
BEFORE_FEED |
Before feed generation | Yes |
AFTER_FEED |
After feed generation | Yes |
BEFORE_SINK |
Before search indexing | Yes |
AFTER_SINK |
After search indexing | Yes |
Lifecycle Stages (observe-only — WEBHOOK, EMIT, LOG, TRIGGER_PIPELINE only, no INTERCEPTOR/SCRIPT):
| Stage | When It Runs | Supported Hook Types |
|---|---|---|
PIPELINE_STARTED |
Pipeline execution begins | WEBHOOK, EMIT, LOG, TRIGGER_PIPELINE |
PIPELINE_COMPLETED |
Pipeline finishes successfully | WEBHOOK, EMIT, LOG, TRIGGER_PIPELINE |
PIPELINE_FAILED |
Pipeline fails | WEBHOOK, EMIT, LOG, TRIGGER_PIPELINE |
ON_ERROR |
When an error occurs | WEBHOOK, EMIT, LOG, TRIGGER_PIPELINE |
ON_RETRY |
When a record is retried | WEBHOOK, EMIT, LOG, TRIGGER_PIPELINE |
ON_DEAD_LETTER |
When a record is sent to dead letter queue | WEBHOOK, EMIT, LOG, TRIGGER_PIPELINE |
Hook Types
Interceptor Hooks
Interceptors run JavaScript code that can modify the records array:
.hooks({
AFTER_EXTRACT: [{
type: 'INTERCEPTOR',
name: 'Add metadata',
code: `
return records.map(r => ({
...r,
extractedAt: new Date().toISOString(),
source: 'supplier-api',
}));
`,
failOnError: false, // Don't fail pipeline if hook fails
timeout: 5000, // 5 second timeout
}],
BEFORE_LOAD: [{
type: 'INTERCEPTOR',
name: 'Filter invalid',
code: `
return records.filter(r => r.sku && r.name);
`,
}],
})
Modify records before search indexing (Meilisearch, Elasticsearch, etc.):
.hooks({
BEFORE_SINK: [{
type: 'INTERCEPTOR',
name: 'Enrich for search',
code: `
return records.map(r => ({
...r,
searchText: [r.name, r.sku, r.description].filter(Boolean).join(' ').toLowerCase(),
facetTags: (r.tags || '').split(',').map(t => t.trim()).filter(Boolean),
boostScore: r.featured ? 1.5 : 1.0,
}));
`,
}],
})
Transform records before CSV/JSON export:
.hooks({
BEFORE_EXPORT: [{
type: 'INTERCEPTOR',
name: 'Format for export',
code: `
return records.map(r => ({
...r,
price: (r.price / 100).toFixed(2),
createdAt: new Date(r.createdAt).toISOString(),
}));
`,
}],
})
Available in interceptor code:
records- The current records arraycontext- Hook context withpipelineId,runId,stage- Standard JavaScript:
Array,Object,String,Number,Date,JSON,Math console.log/warn/error- Logged to pipeline logs
Script Hooks
Script hooks reference pre-registered TypeScript functions. Register scripts via plugin options (recommended) or imperatively:
Via Plugin Options (Recommended):
DataHubPlugin.init({
scripts: {
'addSegment': async (records, context, args) => {
const threshold = args?.threshold || 1000;
return records.map(r => ({
...r,
segment: r.totalSpent > threshold ? 'vip' : 'standard',
}));
},
'validateRequired': async (records, context) => {
return records.filter(r => r.sku && r.name && r.price > 0);
},
'enrichWithTimestamp': async (records, context) => {
return records.map(r => ({
...r,
importedAt: Date.now(),
pipelineRun: context.runId,
}));
},
},
})
Via Service Injection:
import { HookService } from '@oronts/vendure-data-hub-plugin';
@VendurePlugin({ imports: [DataHubPlugin] })
export class MyPlugin implements OnModuleInit {
constructor(private hookService: HookService) {}
onModuleInit() {
this.hookService.registerScript('addSegment', async (records, context, args) => {
const threshold = args?.threshold || 1000;
return records.map(r => ({
...r,
segment: r.totalSpent > threshold ? 'vip' : 'standard',
}));
});
}
}
Tip: When registering scripts via
HookService.registerScript()in a NestJS service, your scripts can access any injected service (database, external APIs, Vendure services) through JavaScript closures. See the Developer Guide for examples.
Use in pipeline:
.hooks({
AFTER_TRANSFORM: [{
type: 'SCRIPT',
scriptName: 'addSegment',
args: { threshold: 5000 },
}],
AFTER_EXTRACT: [{
type: 'SCRIPT',
scriptName: 'validateRequired',
}],
})
Register a script for search index enrichment:
DataHubPlugin.init({
scripts: {
'buildSearchAttributes': async (records, context) => {
return records.map(r => ({
...r,
searchText: [r.name, r.sku, r.description]
.filter(Boolean).join(' ').toLowerCase(),
facetCategories: r.categories?.map(c => c.name) || [],
}));
},
},
})
// Use in pipeline:
.hooks({
BEFORE_SINK: [{ type: 'SCRIPT', scriptName: 'buildSearchAttributes' }],
})
Webhook Hooks
Send HTTP notifications to external systems:
.hooks({
PIPELINE_COMPLETED: [{
type: 'WEBHOOK',
url: 'https://slack.example.com/webhook',
headers: { 'Content-Type': 'application/json' },
}],
PIPELINE_FAILED: [{
type: 'WEBHOOK',
url: 'https://pagerduty.example.com/alert',
secret: 'webhook-signing-secret', // HMAC signature
signatureHeader: 'X-Signature',
retryConfig: {
maxAttempts: 5,
initialDelayMs: 1000,
backoffMultiplier: 2,
},
}],
})
Emit Hooks
Emit Vendure domain events:
.hooks({
PIPELINE_COMPLETED: [{
type: 'EMIT',
event: 'ProductSyncCompleted',
}],
})
Trigger Pipeline Hooks
Start another pipeline with the current records:
.hooks({
AFTER_LOAD: [{
type: 'TRIGGER_PIPELINE',
pipelineCode: 'reindex-search',
}],
})
Testing Hooks
Test hooks without running the full pipeline:
- Go to Data Hub > Hooks
- Select a pipeline
- Choose a hook stage
- Click Test
- View the result and any modifications
Hook Best Practices
- Use interceptors for data modification
- Use webhooks for notifications
- Keep interceptor code simple and fast
- Use script hooks for reusable logic
- Set appropriate timeouts (default: 5000ms)
- Use
failOnError: falsefor non-critical hooks
Import & Export Wizards
The Data Hub provides guided wizards for creating import and export pipelines:
- Go to Data Hub > Pipelines
- Click Import Wizard or Export Wizard
- Follow the step-by-step guide:
- Select a template or start from scratch
- Configure source/destination
- Map fields
- Set trigger and options
- Review and create
Templates
Wizards offer pre-configured templates for common scenarios:
Import Templates: REST API Sync, JSON Import, Magento CSV, XML Feed, ERP Inventory, CRM Customer Sync Export Templates: Google Shopping, Meta Catalog, Amazon Feed, Product CSV/JSON, Order Analytics, Customer GDPR, Inventory Report
Custom templates registered via plugin options or connectors appear alongside built-in templates.
Dry Run
Test pipelines without persisting changes:
- Click Dry Run in the toolbar
- Review the results:
- Summary - Record counts (processed, succeeded, failed)
- Record Diff - Before/after comparison for each step
- Step Details - Timing and record flow per step
- Fix any issues before running the real pipeline
Dry run executes the full pipeline logic but doesn’t commit changes to the database.
Best Practices
Naming
- Use descriptive codes:
product-import-dailynotpipeline-1 - Include frequency:
inventory-sync-hourly - Include source:
erp-product-sync
Testing
- Use Dry Run to test pipelines before production
- Test with small datasets first
- Use the Step Tester to test individual steps
- Validate before running on production data
Error Handling
- Add validation operators to catch bad data early
- Configure error handling strategy:
continue,stop, ordead-letter - Use hooks to send alerts on failures
- Review quarantined records regularly
Performance
- Use batch sizes appropriate for your data
- Limit concurrency for external APIs
- Schedule heavy pipelines during off-peak hours
- Use delta filtering to process only changed records